
|
|
Manual |
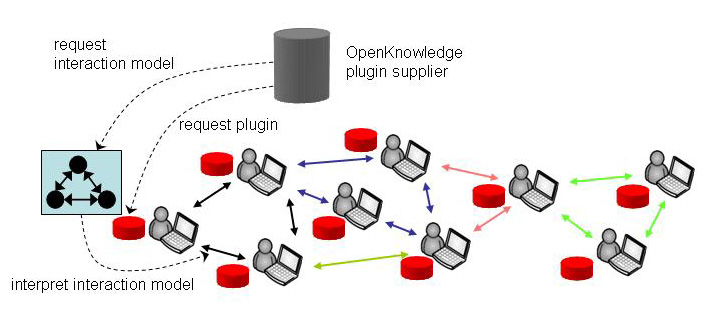
Interaction models are can be shared and used in many different ways but the standard way to use them is by downloading the OpenKnowledge kernel system from www.openk.org. The kernel is a compact program that automatically finds interaction models that you might want to use; allows you to subscribe to interactions that interest you; and interprets the interaction models in which you actually become involved. In the illustration below, the red dots are copies of the kernel system (loaded from the supplier) being run on individual peers.
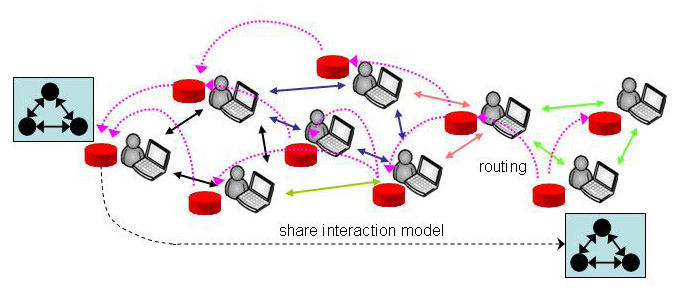
Although our interaction models are portable and could be used by
different systems, there is a social advantage in having many peers
running the same OpenKnowledge kernel. The social advantage comes
from query routing, which works roughly as shown in the picture
below. Suppose that the peer at bottom right of the picture wants to
undertake an interaction but does not have an appropriate interaction
model. That peer would describe the sort of interaction he or she is
seeking, using a sequence of keywords (in a similar way to the way you
search for Web pages in traditional Web browsers). This query then is
routed through the peer network until matching interaction models are
found (in our picture the interaction model in black matches the
query) and are relayed back to the peer. When the peer receives the
interaction model it receives not only the interaction but, through
it, may also access other peers in the network with which it may not
previously have interacted. In this way, sharing interaction models
extends and reinforces social networks.
If you want simply to use interaction models then you do not need to
understand any technical detail of the underlying system because using
an interaction model is analogous to using a program - if the
interaction model is well crafted then it will be easy for an
appropriate group of people to use without them knowing how it is
built. You may, however, want to write your own interaction models or
adapt those you find on the network. This is the topic of the next
section. If you want a broader view of the objectives of OpenKnowledge
then you should read the Openknowledge
manifesto. For a more technical overview of LCC please refer to
the LCC overview paper.
Writing Your Own LCC Interactions
This section explains how to write your own interaction models, which
you can then use and share with others. We begin with a basic example.
Syntax
Each LCC interaction model is defined by a set of clauses where each
clause has the following syntax (in BNF form).
| Clause | := | Role :: Def |
| Role | := | a(Type, Id) |
| Def | := | Role | Message | Def then Def | Def or Def |
| Message | := | M => Role | M => Role <-- C | M <= Role | C <-- M <= Role |
| C | := | Constant | P(Term,...) not(C) | C and C | C or C |
| Id | := | Constant | Variable |
| Term | := | Constant | Variable | P(Term,...) |
| Type | := | Term |
| M | := | Term |
| P | := | Constant |
| Constant | := | Character sequence beginning with an lower case character | number |
| Variable | := | Character sequence beginning with an upper case character |
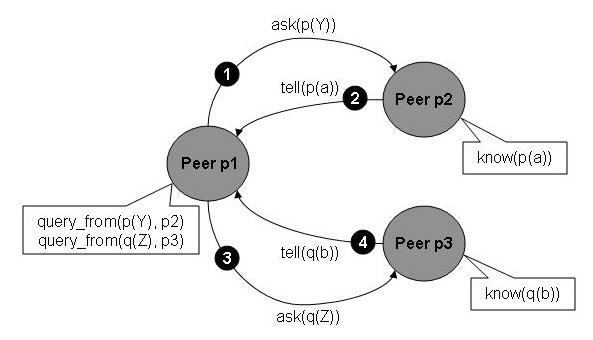
Let us first define an interaction model that does exactly the message passing defined above. There are two roles that agents take in this model: the role of a requester (which asks for information) and the role of an informer (which supplies information). We define a LCC clause for each role as shown below. For the requester (p1) we have simply given the sequence of four messages corresponding to those above. Then we have defined a clause for the role of informer that defines the behaviour expected of p2 and p3.
a(requester, A) ::
ask(X1) => a(informer, p2) <-- query_from(X1, p2) then
tell(X1) <= a(informer, p2) then
ask(X2) => a(informer, p3) <-- query_from(X2, p3) then
tell(X2) <= a(informer, p3)
a(informer, B) ::
ask(X) <= a(requester, B) then
tell(X) => a(requester, B) <-- know(X).
The LCC definition above covers the example but suppose we want a more general type of requester that takes a list, L, of the form [q(Query,Peer),..,], where Query is the query we want to make and Peer is an identifier for the peer to which we want to send the query. We want the requester to send an ask(Query) message to the appropriate Peer for each query and receive a tell(Query) reply each time. A standard way to do this is by giving L as a parameter to the requester role (so it becomes requester(L)) and making the definition of this role recursive, taking the first element of L and then applying the same definition to the remainder of the list, Lr, as shown below.
a(requester(L), A) ::
( ask(Query) => a(informer, Peer) <-- L = [q(Query,Peer) | Lr] then
tell(Query) <= a(informer, Peer) then
a(requester(Lr), A) )
or
null <-- L = [].
a(informer, B) ::
ask(X) <= a(requester(_), B) then
tell(X) => a(requester(_), B) <-- know(X).
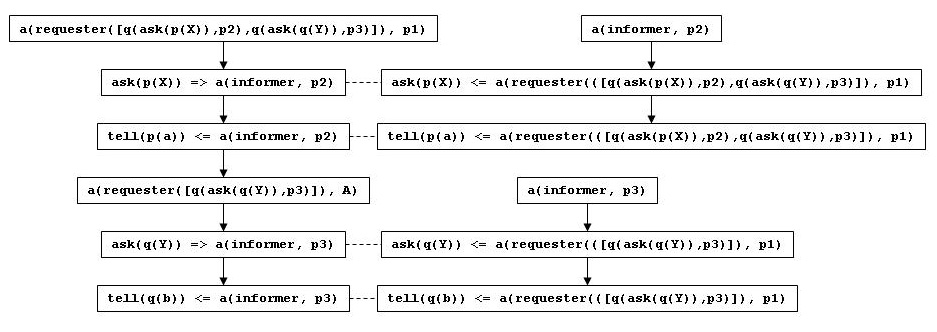
If we were to run the interaction model shown below, starting with the
role of requester for the list of queries
[q(ask(p(X)),p2),q(ask(q(Y)),p3)], then we get the
message sequences shown below. On the left is the sequence for
a(requester([q(ask(p(X)),p2),q(ask(q(Y)),p3)]), p1). On the right are
the sequences for a(informer, p2) and a(informer, p3) which are the
roles undertaken by p2 and p3 in response to p1. The dashed lines
indicate synchronisation via message passing between peers.
a(r1, X) ::
...
M => a(r2, Y) <-- C1
...
a(r2, Y) ::
...
C2 <-- M <= a(r2, X)
...
An example of using this pattern is an interaction that sends a
message, M, to a recipient, Y, where the choice on M is made by the
constraint message(M) and the choice of recipient is made by the
constraint recipient(Y). Acceptance of the message by the recipient
is determined by the constraint accept(M).
a(sender, X) ::
M => a(recipient, Y) <-- message(M) and recipient(Y)
a(recipient, Y) ::
accept(M) <-- M <= a(sender, X)
a(r, X) ::
...
E1 then
E2
...
An example that uses this pattern twice is when the recipient of
the message returns a message to the sender, where response(M1, M2) is
a constraint determining the recipient's response message, M2, from
the sender's message, M1.
a(sender, X) ::
M1 => a(recipient, Y) <-- message(M1) and recipient(Y) then
accept(M2) <-- M2 <= a(recipient, Y)
a(recipient, Y) ::
accept(M1) <-- M1 <= a(sender, X) then
M2 => a(sender, X) <-- response(M1, M2)
a(r, X) ::
E1 <-- C1
or
E2 <-- C2
...
An example of this pattern is when a buyer wants to send a message to
a seller accepting some Offer (received earlier in the definition of
the buyer role) if it is acceptable or otherwise it sends a message to
the seller rejecting that Offer if it is unacceptable.
a(buyer, X) ::
...
accept(Offer) => a(seller, Y) <-- acceptable(Offer)
or
reject(Offer) => a(seller, Y) <-- unacceptable(Offer)
Since LCC makes committed choices, we know in this example that if
acceptable(Offer) is satisfied then the second option (in which the
peer attempts to satisfy unacceptable(Offer)) will not be attempted,
so if testing unacceptability is not important then we might shorten
this example to:
a(buyer, X) ::
...
accept(Offer) => a(seller, Y) <-- acceptable(Offer)
or
reject(Offer) => a(seller, Y)
a(r(A), X) ::
( ... R(A, Ar) ...
a(r(Ar), X) )
or
( ... P(A) ... )
One example of using this pattern is an interaction that sends
as a message each element, M, from a list [M1,...] to peer p2 in role r2.
a(r(A), X) ::
( M => a(r2, p2) <-- A = [M|Ar] then
a(r(Ar), X) )
or
( null <-- A = [] )
A second example is an interaction that sends N messages to peer p2,
each with the same content, M. Here, N and M are parameters to the
role, r.
a(r(N, M), X) ::
( M => a(r2, p2) <-- N > 0 and N1 is N - 1 then
a(r(N1, M), X) )
or
( null <-- N =< 0 )
Many examples of LCC in use for specifying interactions can be found
in the OpenKnowledge publications list.